Hey guys, it’s Yifan again. There has been a lot of progress since my first blog post. As promised last time, I was able to finish a functional prototype with all the legacies left for me. I put the device in the woods to get recording for the first time. The results, to my pleasant surprise, are very impressive. The device recorded 12 hours of data and wrote it to the SD card.
 (Device in the field)
(Device in the field)
 (Device field location)
(Device field location)
The quality of the microphone is quite decent, and although it cannot record birds from far away, it can record the bird on the same tree very clearly. Here are some of my hand-selected bird song clips from the 12 hour recording. Enjoy the sound of nature!
If you did listen to the recordings, hopefully you can tell that one of the recordings is not a bird song (it’s a train whistle). Differentiating between bird calls and noises is a easy task for use human, but it can be a challenge to a computer. Then why do we need to use programs to help us identify these sounds? Take a look at this recording image.

The entire recording is 12 hours, if I choose to hand select out all the bird songs, it can take hours. If we want our device to continuously record for a week, we humans simply do not have the patience to go through hundreds of hours of data. Computers, on the other hand, love analyzing long recordings, and they can be trained to do it very well.
Luckily, pyAudioAnalysis, the library our team uses for classifying different bird species, also has the functionality to segment a long recording based on a mathematical model called Hidden Markov Model (HMM). In the near future, I will hopefully be able to use this method to segment all the recordings from our device.
The process of utilizing HMM model including these following steps. First, you need to generate annotation files for known recordings as training data. The annotation looks like this:
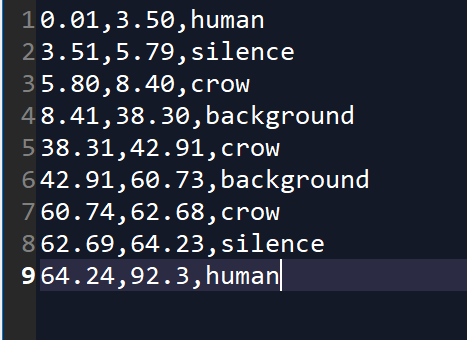
The model is trained by these given class names. After the model is trained, we can then use it to classify an unfamiliar recording. Based on similarities, the model generates marks for segmentation.
In the most recent test run, I trained the model using one single file, and tested the model’s accuracy on a very simple recording. Here is a graph representing the segmentation results.
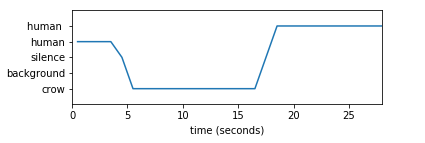

Looks like it’s working, right? Well not really. Although this particular segmentation is pretty accurate, others are not very satisfactory. However, I did only use one training input, which can definitely be improved. Another possible improvement I can think of is to train the model with only two classes: bird and not bird. Since we’ll still have to use the classifier to differentiate different kinds of birds, the segmentation model only needs to be able to tell the difference between birds and non-birds. We will see how that goes. Wish me luck!