
—Written by Nour Chahine—
As you may recall from my introductory blog post, this summer I’m working on building a TinyML device that can guess which card you secretly picked based on your brain’s EEG signal.
But it’s a road paved with many SSVEPs (Steady State Visually Evoked Potentials)!
These past two weeks have been all about SSVEP data collection. I wanted to determine what the optimal experimental conditions would be to elicit SSVEPs in subjects looking at flickering cards. I experimented with brightly lit rooms, dim rooms, and dark rooms. I tested various background colors on the screen and varied the epoch duration of trials to see if this would make a difference in the results.
As expected, there was a huge difference, and I was able to pinpoint the optimal test setup conditions: dimly lit room, 30 second epochs, grey background!
Here is the power spectral density plot of captured from my fellow and subject Sarah, which was recorded at the optimal setup conditions I just described. Notice the distinctive peaks in the EEG frequencies and how they match the card frequencies? All of them are exactly on target!
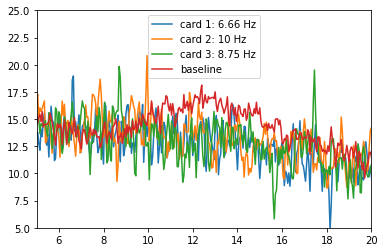
Here is a similar power spectral density plot I collected from Sarah in a brightly lit room, with a black screen background and 20 second epochs.
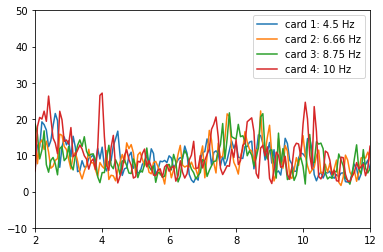
The peaks here are not as distinct as they are in the first setup, and only ONE is on target!
Now that I have my experimental setup figured out, I am testing various flickering frequencies to see which ones elicit the best response consistently among different subjects. So far, I have been getting various responses, where certain frequencies work more for a certain subject and less for another.
Here, I was collecting data from Etienne, and it seemed like the 4.3 Hz, 5 Hz, and 7.5 Hz frequencies worked best for him.
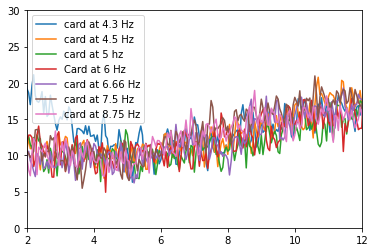
Sam, on the other hand, somehow had most frequencies work for him! (Not sure if I’ll see data as good as his).
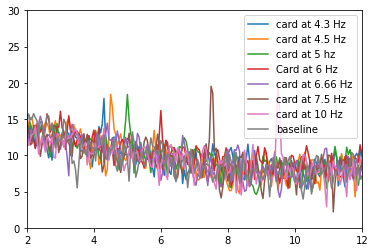
By the end of this week, I will narrow down my frequency choices to the best 4 frequencies that elicited responses consistently among subjects.
Next, I’ll be transforming my data to a format that can be interpreted by the machine learning model, as it would probably fail to process the raw data without any preprocessing. I will be implementing three different approach to accomplish this:
- Using the power spectral density, I will generate a 4-element vector which corresponds to the power of each target frequency. In other words, if my target frequencies are 4.3, 5, 7.5, and 8.75, then my input vector would be the power of the signal at each of these frequencies.
- Using a notch filter to “knock out” the target frequencies, and then “subtracting” the filtered signal from the original signal. This would give me the power of the signal at the specific target frequencies, and this can be used as an input to the model.
- Using a continuous wavelet transform, which is a method to get spectral and temporal features of a signal, I would generate this transform specifically for the target frequencies and use it as my input vector.
So far, I have written the code of the first approach, and I will soon work on codes for the others. I am very excited about the results I have been getting, and I hope to implement them on the Tiny ML model soon enough!