— Written by Fredi Mino —
Hello again! Since the last time we met, I have been working towards producing a machine learning model that can accurately predict the different gestures/finger movements that we are classifying, and (spoiler alert) it seems like we are almost there!
If we are to have any chance of success, we must work on the project incrementally. For this reason, I decided to classify only 5 gestures, moving only one finger at a time, and using the electrode placement described in a previous experiment by BYB. If we get something as basic as this to work, then we can do things like reduce the number of channels needed to produce good classification results and/or add more complex gestures later on.
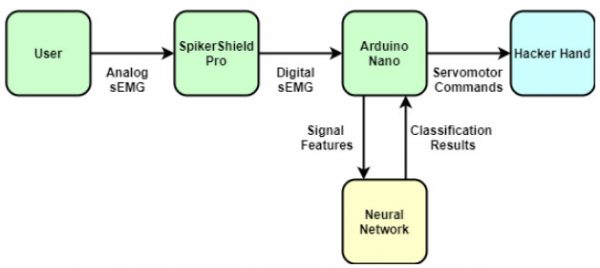
With that in mind, I started by making a high-level block diagram of our system (see image above).
From the diagram, we can identify three main aspects of the project:
- The green blocks require that we understand the physiological aspects of the sEMG signal and the kind of information we can extract from it. Then based on that background knowledge, we need to identify relevant digital signal processing (DSP) techniques to generate a dataset.
- The yellow block will require us to be familiar with neural network properties like neural network architectures, training parameters and performance metrics.
- The blue block requires us to be familiar with hardware control and communication protocols to control peripherals using the Arduino.
As of this update, I have managed to set up a DSP pipeline to generate features for the neural network and observe its performance on training and testing data.
Based on a similar study that worked with sEMG I decided to look at one feature extraction technique that quantifies a muscle’s activation in the time domain. This feature is known as the mean absolute value of the signal and it is defined as:
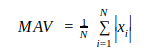
By applying this function to different segments of our signal, we can transform our time series data to a feature vector that the neural network can understand. However, before we even think of using machine learning, we need to make sure that the features for each gesture are at least somewhat separable to our naked eye. To do so, I collected 50 samples per gesture and plotted the average channel activation for each gesture.
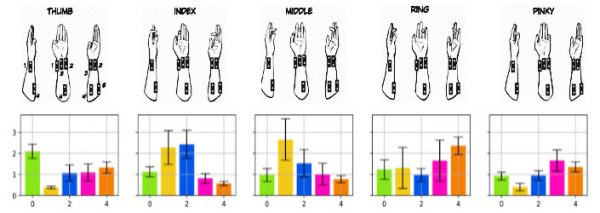
The figure above is showing different activation levels for each channel (colored bars) and for each gesture. It is easy to see from this graph that the average channel activation pattern seems to be unique enough between each gesture. The idea is that if we (humans) can perceive a difference between the profiles, then the neural network might be able to do so as well.
After we have confirmed that our gestures are separable, we feed our labeled MAV features into Edge Impulse. Then we use its really convenient feature generation functionality to show us how each one of our gestures look like in feature space:
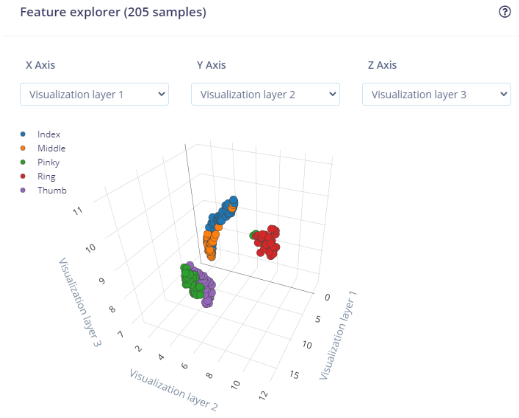
The image above is a solid confirmation that Edge Impulse also perceives the different labels to be separable (note how each gesture cluster is isolated from the others, and there’s almost no mixing between clusters). Therefore, when we train and test the model it comes as no surprise that the classification accuracy for training and testing look like this:
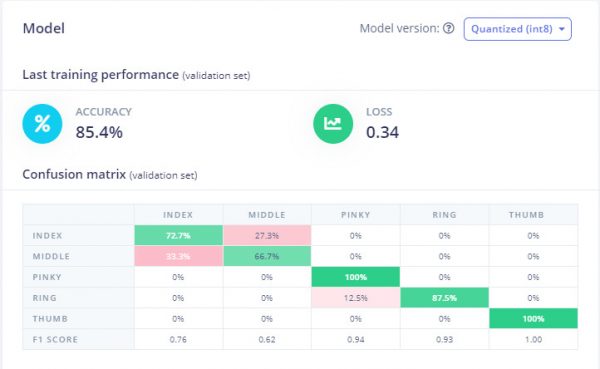
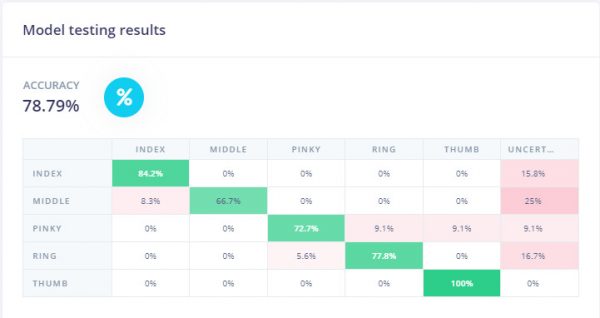
So, is this it? Are we finally done with the TinyML aspect of this project?
Patience, young padawan! Although this is an exciting proof of concept on its own, the dataset was generated using really energetic finger movements (the subject was sore by the end of the recording session…)
Before we can move forward, we need to make sure that our neural network can classify gestures that are more organic and less painful to perform, but that’s a story for another time. Thanks for reading, and I’ll ‘see’ you in the next update!